在特定情况下使用内存池可显著提高性能。
前言
本文仅供学习探讨之用,如果侵犯了您的权益请联系我删除。
工具
需求与思考
- 可限定内存池最大可向系统申请的内存大小
- 尽量保证池中的内存单元都在连续的内存上
- 内存池每次可申请任意大小的内存
- 进行内存的申请时若内存池的空闲空间不足且所需内存未超过内存池最大限定可申请的内存时将进行动态扩容
- 内存单元释放的同时进行临近内存碎片的合并
- 当前需要申请的内存加上已申请的内存若超过限定最大可向系统申请的内存大小时抛出异常
- Garbage Collection
- 内存标记算法
- 内存标记整理算法
- 内存分代标记整理算法
- 当前需要申请的内存加上已申请的内存若超过限定最大可向系统申请的内存大小时启动GC进行垃圾回收
- 若启动GC后仍无法分配内存则抛出异常
内存池数据结构
// 内存单元
struct MemoryUnit
{
uint8_t *data; // 内存单元的数据地址
size_t size; // 内存的数据大小
MemoryBlock *block; // 内存单元所属的内存块
MemoryUnit *nextUnit; // 下一个内存单元
MemoryUnit *prevUnit; // 上一个内存单元
};
// 内存块
struct MemoryBlock
{
uint8_t *data; // 内存块的数据地址
size_t size; // 内存块的数据大小
size_t freeTotal; // 内存块中剩余的空闲内存大小
MemoryUnit *freeList; // 内存块中的空闲内存单元
MemoryUnit *usedList; // 内存块中的已使用内存单元
MemoryBlock *nextBlock; // 下一个内存块
MemoryBlock *prevBlock; // 上一个内存块
};
// 内存池
struct MemoryPool
{
size_t systemPageSize; // 当前操作系统的内存页定义大小
size_t blockMinSize; // 申请内存块时至少申请不能小于块最小大小
size_t poolMaxSize; // 内存池的最大可向系统申请的内存大小
size_t poolSize; // 内存池的当前大小
MemoryBlock *blocks; // 内存块单向循环链表
};
需求的解决方案
- 结构体
MemoryPool的成员poolMaxSize与poolSize用于对比并限定最大可申请的内存大小 - 结构体
MemoryPool的成员blockMinSize用于确保单次申请过小的内存单元导致过多的不连续内存块 - 结构体
MemoryUnit的成员size用于存放当前内存单元所使用的内存大小 - 若当前条件满足动态扩容的条件时,向系统申请新的内存块并使用头插法插入结构体
MemoryPool的成员blocks链表中,这也是将其设计为单项循环链表的原因。与此同此还要更新成员poolSize的数值。 - 内存碎片的合并将会在内存单元释放时自动进行临近单元合并,这也是结构体
MemoryUnit设计为双向链表的原因之一 - 使用当前想要申请的内存大小加上结构体
MemoryPool的成员poolSize的数值进行判断即可
内存池代码定义与实现
类MemoryPool的定义
class MemoryPool
{
public:
struct MemoryBlock;
struct MemoryUnit
{
uint8_t *data;
size_t size;
MemoryBlock *block;
MemoryUnit *nextUnit;
MemoryUnit *prevUnit;
};
struct MemoryBlock
{
uint8_t *data;
size_t size;
size_t freeTotal;
MemoryUnit *freeList;
MemoryUnit *usedList;
MemoryBlock *nextBlock;
MemoryBlock *prevBlock;
};
using unit_t = MemoryUnit;
using block_t = MemoryBlock;
public:
MemoryPool(size_t poolMaxSize = 128 * 1024 * 1024, size_t blockMinSize = 4 * 1024 * 1024);
~MemoryPool();
void *alloc(size_t size);
void free(void *data);
private:
block_t *allocBlock(size_t size);
void freeBlock(block_t *block);
unit_t *allocUnit(size_t size);
void freeUnit(unit_t *unit);
private:
size_t m_systemPageSize = 0;
size_t m_poolMaxSize = 0;
size_t m_blockMinSize = 0;
size_t m_poolSize = 0;
block_t *m_blocks = nullptr;
};
对于MemoryPool::allocBlock方法的实现
MemoryPool::block_t *MemoryPool::allocBlock(size_t size)
{
// allocate memory block
auto alignedSize = size + sizeof(block_t) + sizeof(unit_t);
alignedSize = (alignedSize + (m_systemPageSize - 1)) & ~(m_systemPageSize - 1); // align to system page size
if (m_blockMinSize > alignedSize)
alignedSize = m_blockMinSize;
auto block = reinterpret_cast<block_t *>(::VirtualAlloc(nullptr, alignedSize, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE));
if (nullptr == block)
return nullptr;
// initialize memory block
block->data = reinterpret_cast<uint8_t *>(block) + sizeof(block_t);
block->size = alignedSize - sizeof(block_t);
auto dataPosition = block->data;
// initialize memory used unit
block->usedList = nullptr;
// initialize memory free unit
block->freeList = reinterpret_cast<unit_t *>(dataPosition);
dataPosition += sizeof(unit_t);
block->freeList->data = dataPosition;
block->freeList->size = block->size - (dataPosition - block->data);
block->freeList->nextUnit = block->freeList;
block->freeList->prevUnit = block->freeList;
block->freeList->block = block;
block->freeTotal = block->freeList->size;
// add to block list
if (nullptr != m_blocks)
{
block->prevBlock = m_blocks->prevBlock;
block->nextBlock = m_blocks;
m_blocks->prevBlock->nextBlock = block;
m_blocks->prevBlock = block;
}
else
{
block->prevBlock = block;
block->nextBlock = block;
m_blocks = block;
}
// update pool size
m_poolSize += block->size + sizeof(block_t);
return block;
}
这里在申请内存时确保与当前操作系统内存页定义大小对齐。
对于MemoryPool::freeBlock方法的实现
void MemoryPool::freeBlock(block_t *block)
{
// remove from block list
if (m_blocks->prevBlock == block && m_blocks->nextBlock == block)
m_blocks = nullptr;
else
{
block->prevBlock->nextBlock = block->nextBlock;
block->nextBlock->prevBlock = block->prevBlock;
if (m_blocks == block)
m_blocks = block->nextBlock;
}
// update pool size
m_poolSize -= block->size + sizeof(block_t);
// free memory block
::VirtualFree(block, 0, MEM_RELEASE);
}
对于MemoryPool::allocUnit方法的实现
MemoryPool::unit_t *MemoryPool::allocUnit(size_t size)
{
// check if no block is available
if (nullptr == m_blocks)
return nullptr;
// allocate memory unit
auto block = m_blocks; // first block
do
{
// check if is there no enough memory in the block
if (size > block->freeTotal)
{
block = block->nextBlock;
continue;
}
auto unit = block->freeList; // first free unit
do
{
// check if is there no enough memory in the unit
if (size > unit->size)
{
unit = unit->nextUnit;
continue;
}
// check if unit size is more than wanted size, split unit
if (unit->size > size + sizeof(unit_t))
{
auto newUnit = reinterpret_cast<unit_t *>(unit->data + size);
newUnit->data = unit->data + size + sizeof(unit_t);
newUnit->size = unit->size - size - sizeof(unit_t);
newUnit->nextUnit = unit->nextUnit;
newUnit->prevUnit = unit;
newUnit->block = unit->block;
unit->nextUnit->prevUnit = newUnit;
unit->nextUnit = newUnit;
unit->size = size;
}
// remove unit from free list
unit->prevUnit->nextUnit = unit->nextUnit;
unit->nextUnit->prevUnit = unit->prevUnit;
if (block->freeList == unit)
block->freeList = unit->nextUnit;
// add unit to used list
if (nullptr == block->usedList)
{
block->usedList = unit;
unit->nextUnit = unit;
unit->prevUnit = unit;
}
else
{
unit->nextUnit = block->usedList;
unit->prevUnit = block->usedList->prevUnit;
block->usedList->prevUnit->nextUnit = unit;
block->usedList->prevUnit = unit;
}
// update free total
block->freeTotal -= unit->size;
return unit;
} while (unit != block->freeList);
} while (block != m_blocks);
return nullptr;
}
对于MemoryPool::freeUnit方法的实现
void MemoryPool::freeUnit(unit_t *unit)
{
auto freeSize = unit->size;
// remove unit from used list
if (unit->prevUnit == unit && unit->nextUnit == unit)
unit->block->usedList = nullptr;
else
{
unit->prevUnit->nextUnit = unit->nextUnit;
unit->nextUnit->prevUnit = unit->prevUnit;
if (unit->block->usedList == unit)
unit->block->usedList = unit->nextUnit;
}
// add the unit to the free list, order by address
if (nullptr == unit->block->freeList)
{
unit->nextUnit = unit;
unit->prevUnit = unit;
unit->block->freeList = unit;
}
else
{
auto prevUnit = unit->block->freeList;
auto nextUnit = unit->block->freeList->nextUnit;
if (prevUnit == prevUnit->prevUnit && prevUnit == prevUnit->nextUnit)
{
// combine units if is there near units
if (unit->data + unit->size == reinterpret_cast<uint8_t *>(nextUnit)) // combine next unit
{
unit->size += nextUnit->size + sizeof(unit_t);
unit->nextUnit = unit;
unit->prevUnit = unit;
unit->block->freeList = unit;
}
else if (prevUnit->data + prevUnit->size == reinterpret_cast<uint8_t *>(unit)) // combine prev unit
prevUnit->size += unit->size + sizeof(unit_t);
else // add unit to free list
{
unit->nextUnit = nextUnit;
unit->prevUnit = nextUnit;
nextUnit->prevUnit = unit;
nextUnit->nextUnit = unit;
unit->block->freeList = nextUnit < unit ? nextUnit : unit;
}
}
else
{
// find insert position
while (nextUnit != unit->block->freeList && nextUnit < unit)
{
prevUnit = nextUnit;
nextUnit = nextUnit->nextUnit;
}
// combine the units if is there are near units
if (unit->data + unit->size == reinterpret_cast<uint8_t *>(nextUnit)) // combine next unit
{
unit->size += nextUnit->size + sizeof(unit_t);
unit->nextUnit = nextUnit->nextUnit;
unit->prevUnit = nextUnit->prevUnit;
nextUnit->prevUnit->nextUnit = unit;
nextUnit->nextUnit->prevUnit = unit;
nextUnit = nextUnit->nextUnit;
}
if (prevUnit->data + prevUnit->size == reinterpret_cast<uint8_t *>(unit)) // combine prev unit
{
prevUnit->size += unit->size + sizeof(unit_t);
prevUnit->nextUnit = nextUnit;
nextUnit->prevUnit = prevUnit;
}
}
}
// update free total
m_blocks->freeTotal += freeSize;
}
这4个主要的方法实现好之后就是MemoryPool::alloc与MemoryPool::free两个方法的实现了,我们要做的只需要对上面4个方法进行逻辑的封装就好了。
对于MemoryPool::alloc方法的实现
void *MemoryPool::alloc(size_t size)
{
if (0 == size)
return nullptr;
if (nullptr == m_blocks)
m_blocks = allocBlock(size);
auto unit = allocUnit(size);
if (nullptr == unit)
{
if (size + m_poolSize > m_poolMaxSize)
throw std::bad_alloc();
auto block = allocBlock(size);
if (nullptr == block)
return nullptr;
unit = allocUnit(size);
if (nullptr == unit)
return nullptr;
}
return unit->data;
}
对于MemoryPool::free方法的实现
void MemoryPool::free(void *data)
{
if (nullptr == data)
return;
auto unit = reinterpret_cast<unit_t *>(reinterpret_cast<uint8_t *>(data) - sizeof(unit_t));
if (nullptr == unit)
return;
if (nullptr == unit->block)
return;
freeUnit(unit);
}
到这里,内存池的主体已经搭建好了,那接下来就对比一下性能。
性能对比
测试用的代码如下
MemoryPool g_memoryPool(1 * 1024 * 1024 * 1024);
template <typename runable_t>
struct RunTickCount
{
runable_t &&runable;
uint64_t operator()() const noexcept
{
auto result = __rdtsc();
runable();
return __rdtsc() - result;
}
};
void test01()
{
for (size_t i = 0; i < 100; i++)
{
auto data = new char[8 * 1024 * 1024];
delete[] data;
}
}
void test02()
{
for (size_t i = 0; i < 100; i++)
{
auto data = ::VirtualAlloc(nullptr, 8 * 1024 * 1024, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
::VirtualFree(data, 0, MEM_RELEASE);
}
}
void test03()
{
for (size_t i = 0; i < 100; i++)
{
auto data = g_memoryPool.alloc(8 * 1024 * 1024);
g_memoryPool.free(data);
}
}
void test04()
{
for (size_t i = 0; i < 100; i++)
auto data = new char[8 * 1024 * 1024];
}
void test05()
{
for (size_t i = 0; i < 100; i++)
auto data = ::VirtualAlloc(nullptr, 8 * 1024 * 1024, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
}
void test06()
{
for (size_t i = 0; i < 100; i++)
auto data = g_memoryPool.alloc(8 * 1024 * 1024);
}
int main()
{
try
{
std::cout << "[*] test 100 loop with allocating and freeing the memory of 8MB" << std::endl;
std::cout << "[=] std new-delete time: " << RunTickCount<decltype(test01)>{test01}() << " ticks" << std::endl;
std::cout << "[=] windows virtualAlloc-Free time: " << RunTickCount<decltype(test02)>{test02}() << " ticks" << std::endl;
std::cout << "[=] memory pool alloc-free time: " << RunTickCount<decltype(test03)>{test03}() << " ticks" << std::endl;
std::cout << "[=] std just new time: " << RunTickCount<decltype(test04)>{test04}() << " ticks" << std::endl;
std::cout << "[=] windows just virtualAlloc time: " << RunTickCount<decltype(test05)>{test05}() << " ticks" << std::endl;
std::cout << "[=] memory pool just alloc time: " << RunTickCount<decltype(test06)>{test06}() << " ticks" << std::endl;
std::cout << "[+] test passed" << std::endl;
}
catch (const std::exception &e)
{
std::cerr << "[-] " << e.what() << std::endl;
}
return 0;
}
编译使用的参数cl .\test_memorypool.cc /O2 /EHsc /std:c++20
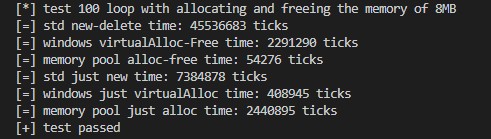
这里仅用WindowsAPI与内存池的性能做比较,对于new与delete就当看个乐呵。
可以看到,内存池在循环申请与释放的测试中一骑绝尘。
这是因为在freeUnit时我们并没有真的把内存还给系统,而是交给内存池来保管。
而第二次进入allocUnit时因为还有可用的内存,所以可以直接分配,不需要向系统申请新的内存!
但是内存池在仅申请内存不释放的测试中被WindowsAPI所击败,这是因为仅申请内存的话调用WindowsAPI仅需一次VirtualAlloc的费用。
而内存池每次进行动态扩容时,不仅需要一次VirtualAlloc的费用,还需要对内存池中的各项参数进行调整,所以导致费用升高。
那么是因为这个内存池太垃圾了?其实不然,我们默认设定了内存池的最小块大小时4MB,而每次申请的内存大小为8MB,这就导致了内存池需要不断地进行动态扩容。
如果我们这里把内存池的块内存大小设置的更大,或者说我们每次申请的内存大小并不超过默认块大小,那么情况又会有所不同。
我们把每次申请的内存大小修改为4KB
void test05()
{
for (size_t i = 0; i < 100; i++)
auto data = ::VirtualAlloc(nullptr, 4 * 1024, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
}
void test06()
{
for (size_t i = 0; i < 100; i++)
auto data = g_memoryPool.alloc(4 * 1024);
}
再来看结果
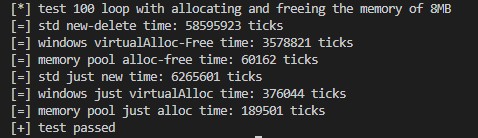
这次轮到WindowsAPI被内存池击败了。由此可见,并不是所有情况下内存池都是适用的,仅在特定情况下内存池能较好的发挥其作用。
接下来我们写一段程序来dump内存池的内存结构,了解一下在freeUnit时究竟发生了什么。
内存池释放单元时的Graphviz图
先修改一下代码,创建一个新的类MemoryPoolX并继承MemoryPool,我们将在这个类里面进行dump操作
class MemoryPoolX final : public MemoryPool
{
public:
MemoryPoolX(size_t poolMaxSize = 128 * 1024 * 1024, size_t blockMinSize = 4 * 1024 * 1024)
: MemoryPool(poolMaxSize, blockMinSize)
{
}
~MemoryPoolX()
{
}
void dumpGraphviz()
{
std::ofstream out("test_memorypool.dot");
out << "digraph DataStructure {\n";
out << "node [shape=record];\n";
out << "\"" << this << "\" [label=\"{<f0>MemoryPool|"
<< this << "|"
<< "{systemPageSize|" << m_systemPageSize << "}|"
<< "{poolMaxSize|" << m_poolMaxSize << "}|"
<< "{blockMinSize|" << m_blockMinSize << "}|"
<< "{poolSize|" << m_poolSize << "}|"
<< "{<f1>blocks|" << m_blocks << "}"
<< "}\" color=\"#409eff\"];\n";
block_t *block = m_blocks;
do
{
out << "\"" << block << "\" [label=\"{<f0>MemoryBlock|"
<< block << "|"
<< "{data|" << block->data << "}|"
<< "{size|" << block->size << "}|"
<< "{freeTotal|" << block->freeTotal << "}|"
<< "{<f1>freeList|" << block->freeList << "}|"
<< "{<f2>usedList|" << block->usedList << "}|"
<< "{<f3>nextBlock|" << block->nextBlock << "}|"
<< "{<f4>prevBlock|" << block->prevBlock << "}"
<< "}\" color=\"#909399\"];\n";
unit_t *unit = block->usedList;
do
{
out << "\"" << unit << "\" [label=\"{<f0>MemoryUnit|"
<< unit << "|"
<< "{data|" << unit->data << "}|"
<< "{size|" << unit->size << "}|"
<< "{block|" << unit->block << "}|"
<< "{<f1>nextUnit|" << unit->nextUnit << "}|"
<< "{<f2>prevUnit|" << unit->prevUnit << "}"
<< "}\" color=\"#f56c6c\"];\n";
if (unit == block->usedList)
{
out << "subgraph cluster_" << unit << " {\n"
<< "label=\"usedList\";\n";
out << "\"" << block << "\":f2 -> \"" << unit << "\":f0 [style=\"dotted\" color=\"#0000ff\"];\n";
}
else
out << "\"" << unit->nextUnit << "\":f2 -> \"" << unit << "\":f0 [style=\"dotted\" color=\"#0000ff\"];\n";
unit = unit->nextUnit;
} while (unit != block->usedList);
out << "}\n";
unit = block->freeList;
do
{
out << "\"" << unit << "\" [label=\"{<f0>MemoryUnit|"
<< unit << "|"
<< "{data|" << unit->data << "}|"
<< "{size|" << unit->size << "}|"
<< "{block|" << unit->block << "}|"
<< "{<f1>nextUnit|" << unit->nextUnit << "}|"
<< "{<f2>prevUnit|" << unit->prevUnit << "}"
<< "}\" color=\"#67c23a\"];\n";
if (unit == block->freeList)
{
out << "subgraph cluster_" << unit << " {\n"
<< "label=\"freeList\";\n";
out << "\"" << block << "\":f1 -> \"" << unit << "\":f0 [style=\"dashed\" color=\"#0000ff\"];\n";
}
else
out << "\"" << unit->nextUnit << "\":f1 -> \"" << unit << "\":f0 [style=\"dashed\" color=\"#0000ff\"];\n";
unit = unit->nextUnit;
} while (unit != block->freeList);
out << "}\n";
if (block == m_blocks)
out << "\"" << this << "\":f1 -> \"" << block << "\":f0 [color=\"#0000ff\"];\n";
else
out << "\"" << block->nextBlock << "\":f3 -> \"" << block << "\":f0 [color=\"#0000ff\"];\n";
block = block->nextBlock;
} while (block != m_blocks);
out << "}";
out.close();
}
};
MemoryPoolX g_memoryPool(1 * 1024 * 1024 * 1024);
void dumpGraphviz()
{
std::vector<void *> datas;
for (size_t i = 0; i < 6; i++)
datas.push_back(g_memoryPool.alloc(i * 1024));
datas.push_back(g_memoryPool.alloc(8 * 1024 * 1024));
datas.push_back(g_memoryPool.alloc(8 * 1024 * 1024));
g_memoryPool.dumpGraphviz();
std::cout << "dump01" << std::endl;
getchar();
g_memoryPool.free(datas[2]);
g_memoryPool.dumpGraphviz();
std::cout << "dump02" << std::endl;
getchar();
g_memoryPool.free(datas[3]);
g_memoryPool.dumpGraphviz();
std::cout << "dump03" << std::endl;
getchar();
}
然后在main函数中调用dumpGraphviz就好了,直接看结果(若看不清可对着图片右键,然后选择在新标签页中打开图片)
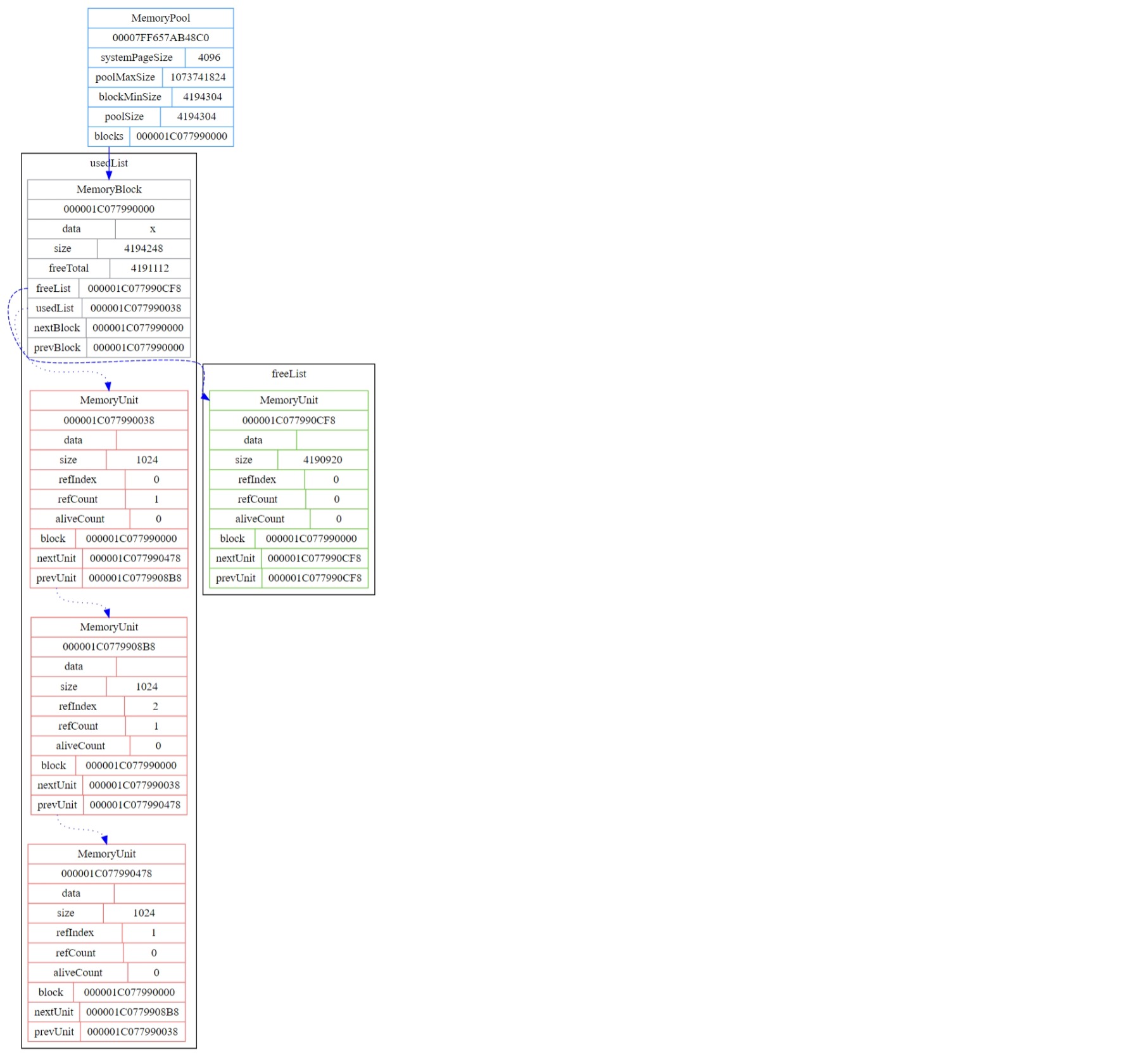
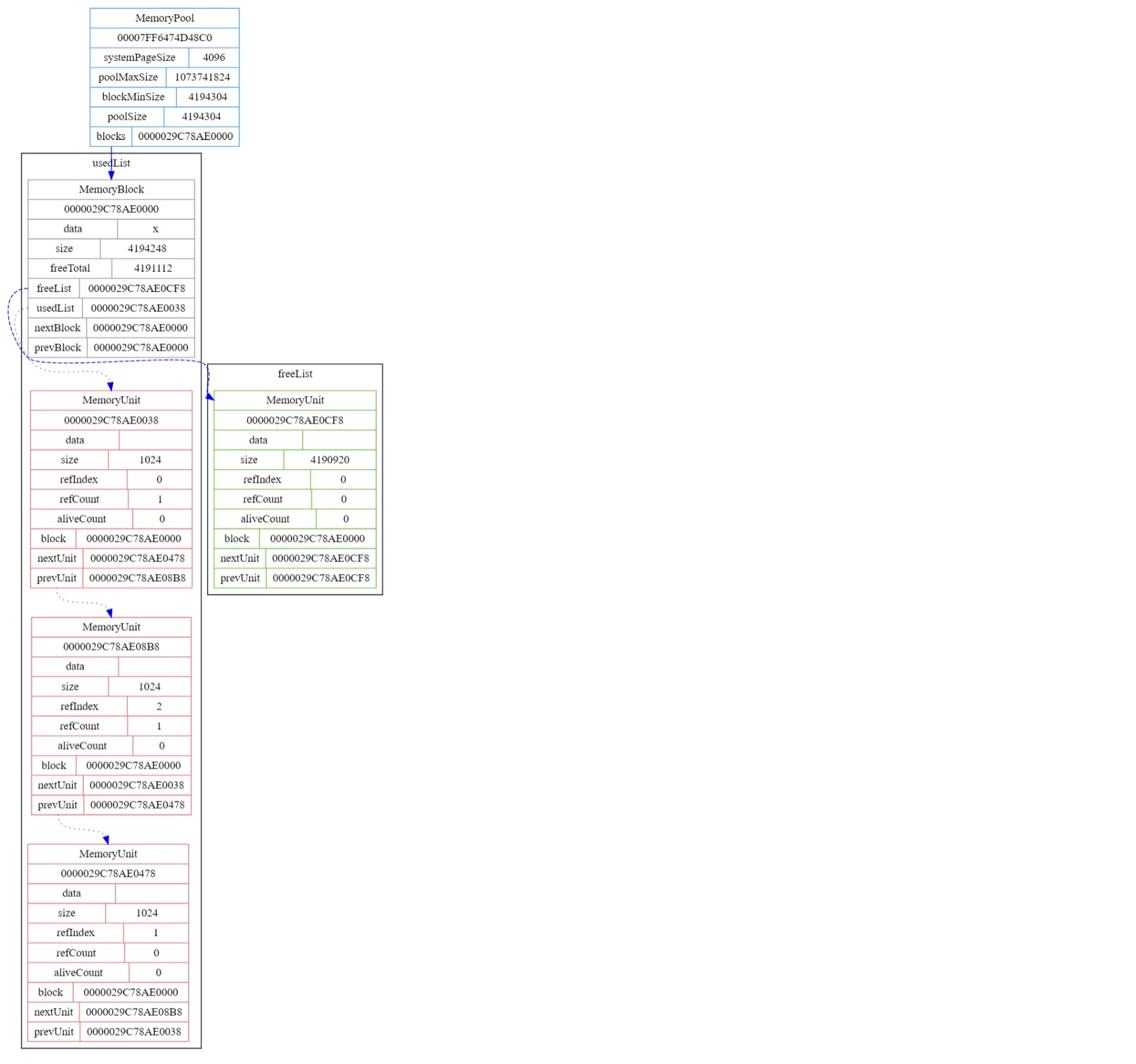
申请完内存后的内存布局情况,其中红色为已使用的,绿色为空闲的
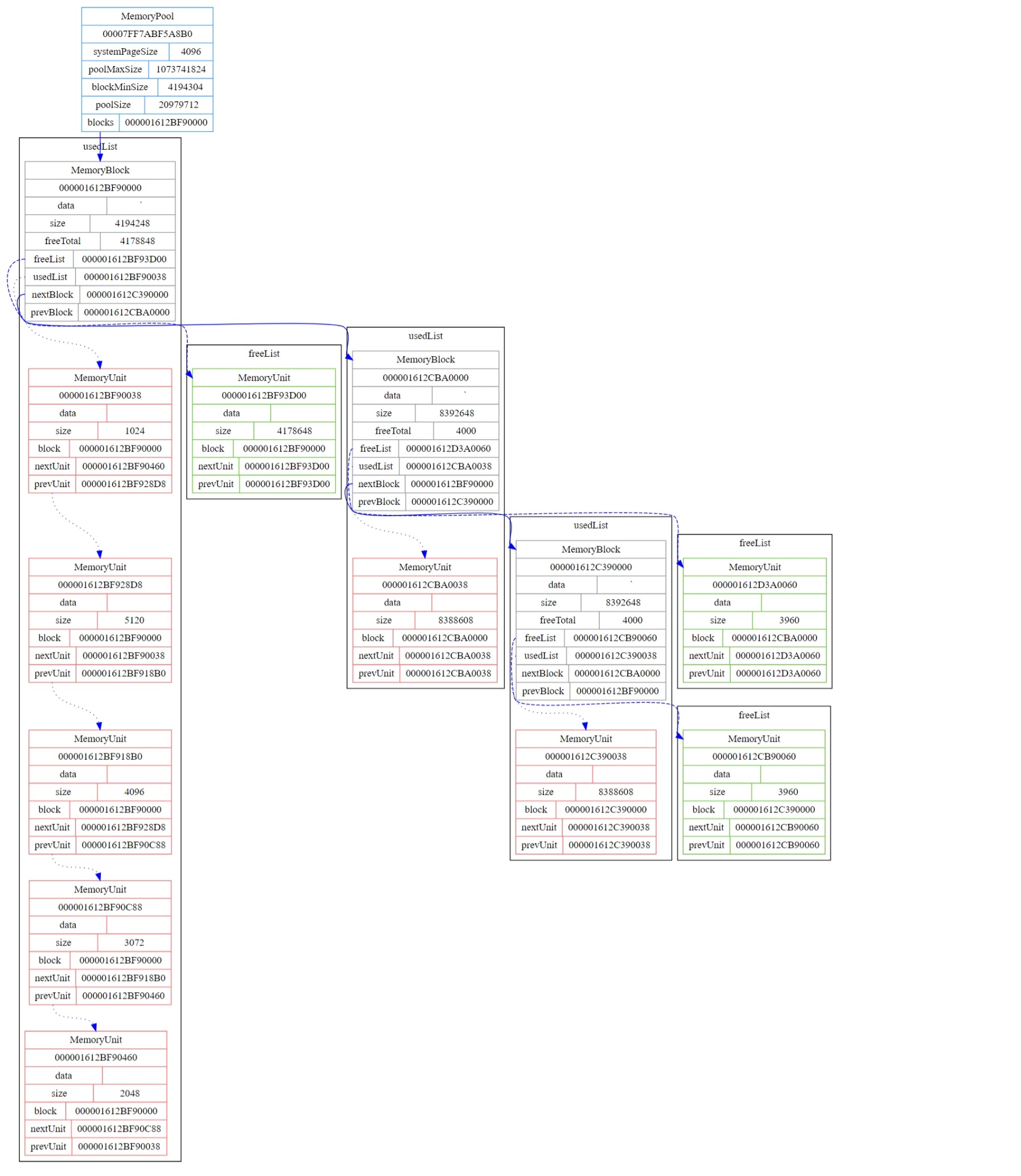
释放大小为2048的这个内存单元后的内存布局情况

可以看到第一个内存块的空闲内存单元链表中多出了一个大小为2048的空闲内存单元,因为其与大小为4178648的空闲内存单元并不临近,所以并没有进行内存单元(碎片)的合并。
释放大小为3072的这个内存单元后的内存布局情况
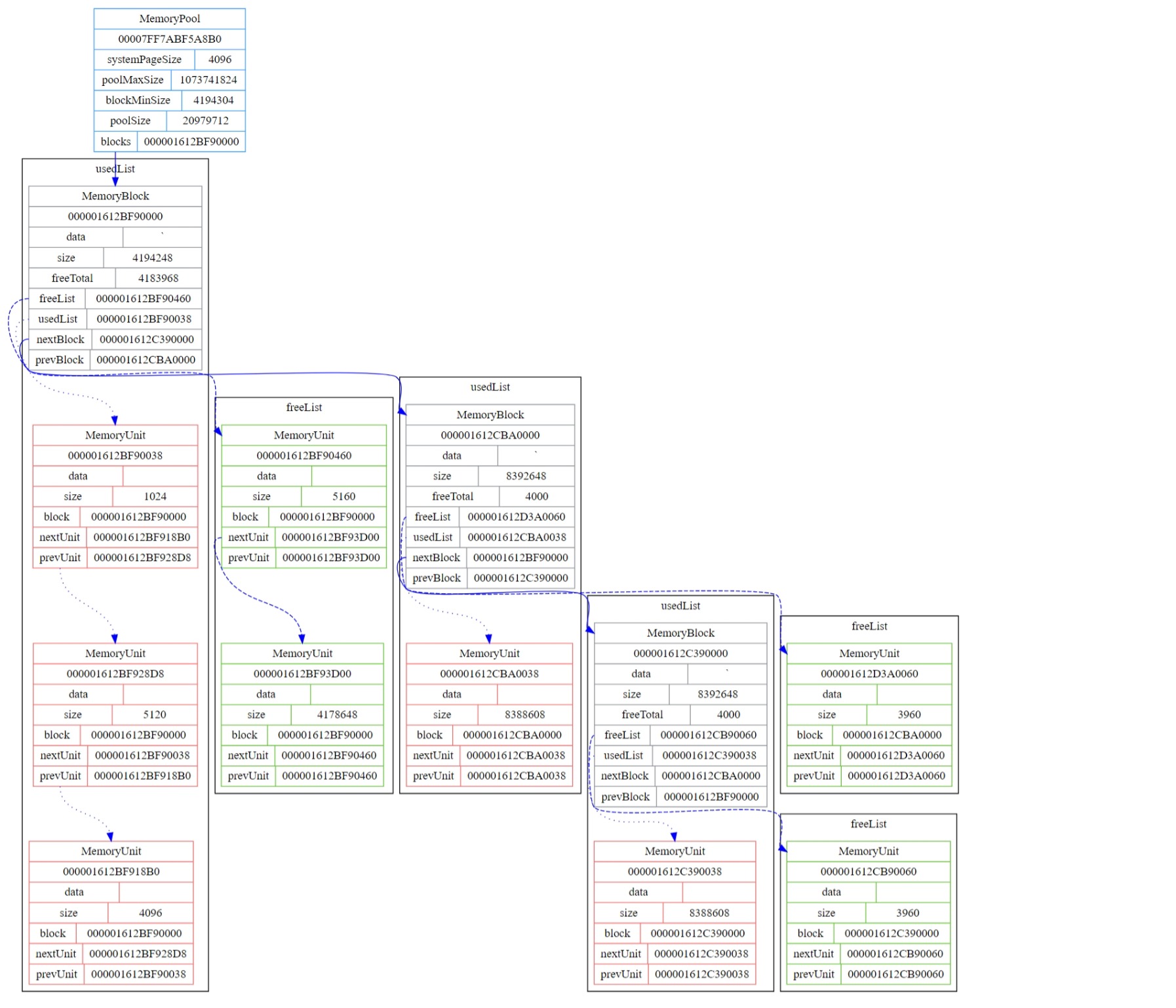
在释放大小为3072的内存单元的同时检测到其与大小为2048的空闲内存单元为临近内存单元,所以会进行碎片的合并。
为什么会生成一个大小为5160的空闲内存单元而不是大小为5120的单元是因为合并成一个时需要丢弃被合并的内存单元的头部信息,而头部信息占用的内存大小为40字节,因此合并后就是5160字节。其他单元依此类推。
到这里,内存池的内容基本就讲完了,接下来我们来看看垃圾回收机制。
Garbage Collection
注意:这里所说的标记使用的是引用计数的方式来模拟,真正的GC中不应出现引用计数这种东西。
其实个人觉得在C++中使用GC的意义不大,虽然会更方便一点,但是使用智能指针与作用域限定进行自动内存管理其实也差不多,所以GC这里的内容就算是写着玩的了。
想要在C++中实现GC,我们要做的第一件事情是要对raw pointer进行封装,因为如果使用的是raw pointer的话,我们无法对数据的引用进行更新,也无法跟踪指针的使用。例如:GC运行后仍有未知代码对被GC的指针(raw pointer)进行访问,造成程序的崩溃。
原始指针的封装
我们这里使用引用计数的方式来跟踪指针,上代码。
先给内存单元添加三个属性
// 内存单元
struct MemoryUnit
{
uint8_t *data; // 内存单元的数据地址
size_t size; // 内存的数据大小
size_t refIndex; // 内存单元引用表的对应的索引(用于内存整理算法更新引用)
size_t refCount; // 内存单元引用计数(用于内存标记算法)
size_t aliveCount; // 内存单元的GC存活计数(用于分代理论)
MemoryBlock *block; // 内存单元所属的内存块
MemoryUnit *nextUnit; // 下一个内存单元
MemoryUnit *prevUnit; // 上一个内存单元
};
然后给MemoryPool添加一个成员std::unordered_map<size_t, unit_t *> m_refUnits,用来记录用于整理算法的指针引用。并添加一个[]运算符的重载
unit_t *operator[](size_t index)
{
return m_refUnits[index];
}
方便对于内存单元的访问。
原始指针的封装类
class GCMemory
{
public:
friend MemoryPool;
public:
GCMemory(MemoryPool *pool, size_t unitIndex)
: m_pool(pool),
m_unitIndex(unitIndex)
{
(*m_pool)[m_unitIndex]->refCount++;
}
GCMemory()
: m_pool(nullptr),
m_unitIndex(0)
{
}
~GCMemory()
{
if (nullptr == m_pool)
return;
auto unit = (*m_pool)[m_unitIndex];
if (nullptr != unit)
unit->refCount--;
}
GCMemory(GCMemory &other)
: m_pool(other.m_pool)
{
(*m_pool)[m_unitIndex]->refCount++;
}
GCMemory(GCMemory &&other)
: m_pool(other.m_pool)
{
other.m_pool = nullptr;
}
GCMemory &operator=(GCMemory &other)
{
m_pool = other.m_pool;
(*m_pool)[m_unitIndex]->refCount++;
return *this;
}
GCMemory &operator=(GCMemory &&other)
{
m_pool = other.m_pool;
other.m_pool = nullptr;
return *this;
}
GCMemory &operator++()
{
(*m_pool)[m_unitIndex]->refCount++;
return *this;
}
GCMemory &operator--()
{
auto unit = (*m_pool)[m_unitIndex];
if (unit->refCount > 0)
unit->refCount--;
return *this;
}
operator bool() const
{
auto unit = (*m_pool)[m_unitIndex];
return nullptr != m_pool && nullptr != unit && unit->refCount > 0;
}
operator void *() const noexcept
{
auto unit = (*m_pool)[m_unitIndex];
return nullptr == unit ? nullptr : unit->data;
}
operator uint8_t *() const noexcept
{
auto unit = (*m_pool)[m_unitIndex];
return nullptr == unit ? nullptr : unit->data;
}
private:
MemoryPool *m_pool;
size_t m_unitIndex;
};
using gc_t = GCMemory;
对于MemoryPool::allocGC方法的实现
MemoryPool::gc_t MemoryPool::allocGC(size_t size)
{
if (0 == size)
return {};
if (nullptr == m_blocks)
m_blocks = allocBlock(size);
auto unit = allocUnit(size);
if (nullptr == unit)
{
if (size + m_poolSize > m_poolMaxSize)
throw std::bad_alloc();
auto block = allocBlock(size);
if (nullptr == block)
return {};
unit = allocUnit(size);
if (nullptr == unit)
return {};
}
static size_t unitIndex = 0;
m_refUnits[unitIndex] = unit;
unit->refIndex = unitIndex++;
unit->refCount = 0;
unit->aliveCount = 0;
return gc_t(this, unit->refIndex);
}
那么来稍微测试一下
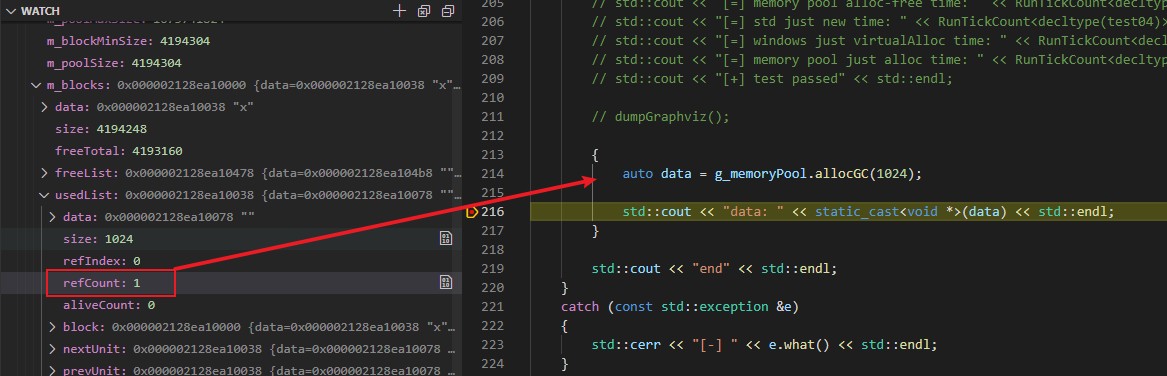
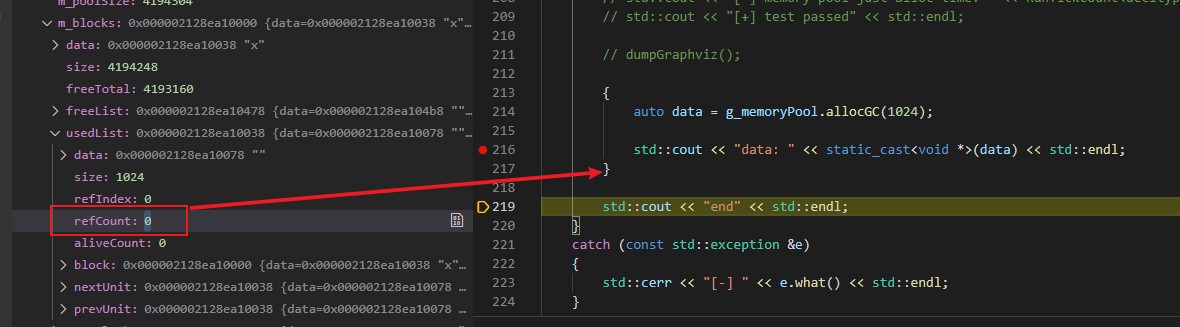
可以看到,在刚申请完的时候引用计数为1,并在走出作用域后变为了0。
内存标记算法
void MemoryPool::markedGC()
{
for (auto &unit : m_refUnits)
{
if (0 != unit.second->refCount)
continue;
freeUnit(unit.second);
unit.second = nullptr;
}
}
这个其实没什么好说的,当发生GC的时候检查内存单元的引用计数,若为0则表示没有使用,进行内存的回收。
看一下效果
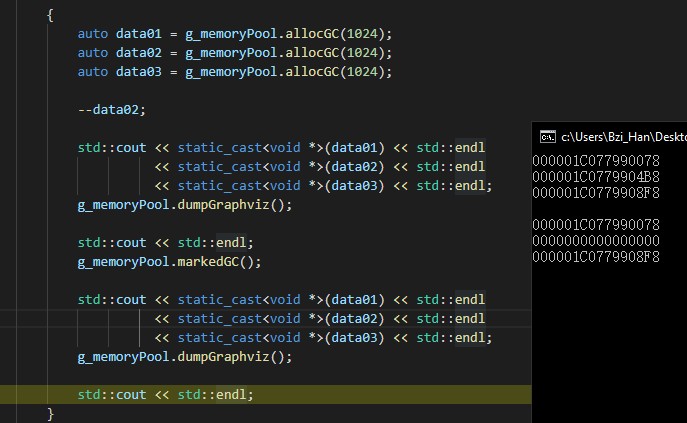
在这里我们手动将data02的引用计数-1来模拟无引用的情况。
可以看到,在执行GC之后引用计数为0的data02的引用指针变成了nullptr,说明GC运行成功。正常情况下只论标记回收算法的话内存池会产生大量的内存碎片,但我们这里在释放的时候会自动进行临近碎片的合并,所以情况其实还好。
看一下内存结构变化的Graphviz图,对应代码中两处g_memoryPool.dumpGraphviz()的调用。
 |
 |
|---|
注意:对于后面将要说的两种算法来说,当前的内存池模型属于冗余设计。实际设计时因为存在整理算法,所以freeList、usedList这些都可以不要,直接使用一个成员标记最后申请的位置即可。在下次进入申请内存时仅需判断当前块是否有足够的空闲内存,如果没有则动态扩容,否则可直接返回最后申请的位置,在这种情况下算法的时间复杂度仅为O(1)
内存标记整理算法
在实现整理算法之前还需要两个特别重要的方法需要实现,分别是suspendTheWorld与resumeTheWorld。
在我们进行内存整理之前需要先对当前进程的除当前线程外的所有线程进行暂停,因为在我们进行整理的过程中不允许出现被整理内存被其他线程访问的情况,否则可能会导致出现数据错误甚至崩溃等问题。
上代码
std::vector<HANDLE> MemoryPool::suspendTheWorld()
{
std::vector<HANDLE> threadHandles;
auto currentProcessId = ::GetCurrentProcessId();
auto currentThreadId = ::GetCurrentThreadId();
auto snapshotHandle = ::CreateToolhelp32Snapshot(TH32CS_SNAPTHREAD, 0);
if (nullptr != snapshotHandle)
{
THREADENTRY32 threadEntry{};
threadEntry.dwSize = sizeof(threadEntry);
if (!::Thread32First(snapshotHandle, &threadEntry))
return threadHandles;
do
{
if (currentProcessId != threadEntry.th32OwnerProcessID || currentThreadId == threadEntry.th32ThreadID)
continue;
auto handle = ::OpenThread(THREAD_ALL_ACCESS, false, threadEntry.th32ThreadID);
if (nullptr == handle)
throw std::exception("OpenThread failed");
if (-1 == ::SuspendThread(handle))
throw std::exception("SuspendThread failed");
threadHandles.push_back(handle);
} while (::Thread32Next(snapshotHandle, &threadEntry));
::CloseHandle(snapshotHandle);
}
return threadHandles;
}
void MemoryPool::resumeTheWorld(std::vector<HANDLE> &handles)
{
for (auto &handle : handles)
{
if (-1 == ::ResumeThread(handle))
throw std::exception("ResumeThread failed");
::CloseHandle(handle);
}
}
这两个方法实现之后再来实现内存标记整理算法
void MemoryPool::markedTidyingGC()
{
std::set<unit_t *> aliveUnits;
std::vector<unit_t *> deadUnits;
auto threadHandles = suspendTheWorld(); // 砸瓦鲁多
auto block = m_blocks;
do
{
aliveUnits.clear();
deadUnits.clear();
auto unit = block->usedList;
do
{
if (0 != unit->refCount)
aliveUnits.insert(unit);
else
deadUnits.push_back(unit);
unit = unit->nextUnit;
} while (unit != block->usedList);
// check if alive units is empty
if (aliveUnits.empty())
{
// free all dead units
for (auto &unit : deadUnits)
{
m_refUnits[unit->refIndex] = nullptr;
freeUnit(unit);
}
}
else
{
// update dead unit reference
for (const auto &unit : deadUnits)
m_refUnits[unit->refIndex] = nullptr;
// move alive units to the front of the block
auto unitMoveToPosition = reinterpret_cast<unit_t *>(block->data);
size_t usedTotalSize = 0;
for (auto &unit : aliveUnits)
{
memcpy(unitMoveToPosition, unit, sizeof(unit_t) + unit->size);
unitMoveToPosition->data = reinterpret_cast<uint8_t *>(unitMoveToPosition) + sizeof(unit_t);
if (0 == usedTotalSize)
{
block->usedList = unitMoveToPosition;
unitMoveToPosition->nextUnit = unitMoveToPosition;
unitMoveToPosition->prevUnit = unitMoveToPosition;
}
else
{
block->usedList->prevUnit->nextUnit = unitMoveToPosition;
unitMoveToPosition->prevUnit = block->usedList->prevUnit;
unitMoveToPosition->nextUnit = block->usedList;
block->usedList->prevUnit = unitMoveToPosition;
}
usedTotalSize += unitMoveToPosition->size + sizeof(unit_t);
unitMoveToPosition = reinterpret_cast<unit_t *>(unitMoveToPosition->data + unitMoveToPosition->size);
}
// reset free unit list
block->freeTotal = block->size - usedTotalSize - sizeof(unit_t);
block->freeList = reinterpret_cast<unit_t *>(block->data + usedTotalSize);
block->freeList->data = reinterpret_cast<uint8_t *>(block->freeList) + sizeof(unit_t);
block->freeList->block = block;
block->freeList->size = block->freeTotal;
block->freeList->nextUnit = block->freeList;
block->freeList->prevUnit = block->freeList;
// update used unit reference
unit = block->usedList;
do
{
m_refUnits[unit->refIndex] = unit;
unit = unit->nextUnit;
} while (unit != block->usedList);
}
block = block->nextBlock;
} while (block != m_blocks);
resumeTheWorld(threadHandles); // 使用相同类型的替身
}
可以看到整个整理的过程就是先暂停世界,然后记录在此次GC中仙去与存活的内存单元。
如果此次GC没有存活的内存单元则直接直接进行内存单元的释放,否则先进行仙去内存单元的指针引用更新,使其变为nullptr,接下来对存活内存单元进行数据移动,将整个内存单元移动至前一个内存单元的后面,使其紧密贴合,如果是第一个移动的话则移动的目标地址是当前内存块的数据地址。
你问我会不会后面的数据把前面的单元给覆盖了?自然是不会,这是为什么使用std::set而不是std::vector、std::unordered_set等容器来存放存活内存单元地址的原因,因为std::set会自动给我们进行排序,而只要我们保证存活内存单元的移动是顺序的,就不会发生数据覆盖的情况。
小提示:std::set基于红黑树实现,如果不需要排序的功能可使用std::unordered_set,std::unordered_set的实现基于哈希表,在性能上可直接吊打
在移动完所有存活的内存单元之后我们需要更新空闲内存空间的信息,因为我们已将使用的内存单元移动到内存块首部,所以剩下的都是可使用的空闲内存,直接分配一个大块空闲内存单元就好了。
最后我们需要更新已使用的内存单元的指针引用信息并取消整个世界的暂停即可。
看效果

运行过程内存结构变化的Graphviz图
 |
 |
|---|
可以看到data02被释放后原本使用的地址被data03拿去用了,说明移动整理成功。
内存分代标记整理算法
提示:因当前内存池结构不太好实现分代,所以接下来会另外申请一块内存来当作老年代
代码
void MemoryPool::generationalMarkedTidyingGC()
{
static unit_t *elderUnitList = reinterpret_cast<unit_t *>(::VirtualAlloc(nullptr, 32 * 1024 * 1024, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE));
static size_t elderUnitListIndex = 0;
if (nullptr == elderUnitList)
throw std::exception("Emulate elder block failed");
std::set<unit_t *> elderUnits;
std::set<unit_t *> aliveUnits;
std::vector<unit_t *> deadUnits;
auto threadHandles = suspendTheWorld(); // 砸瓦鲁多
auto block = m_blocks;
do
{
if (nullptr == block->usedList)
{
block = block->nextBlock;
continue;
}
elderUnits.clear();
aliveUnits.clear();
deadUnits.clear();
auto unit = block->usedList;
do
{
if (0 != unit->refCount)
{
if (4 <= ++unit->aliveCount)
elderUnits.insert(unit);
else
aliveUnits.insert(unit);
}
else
deadUnits.push_back(unit);
unit = unit->nextUnit;
} while (unit != block->usedList);
// check if alive units and elder units is empty
if (aliveUnits.empty() && elderUnits.empty())
{
// free all dead units
for (auto &unit : deadUnits)
{
m_refUnits[unit->refIndex] = nullptr;
freeUnit(unit);
}
}
else
{
// update dead unit reference
for (const auto &unit : deadUnits)
m_refUnits[unit->refIndex] = nullptr;
// move elder units to the front of the elder block
for (auto &unit : elderUnits)
{
memcpy(elderUnitList + elderUnitListIndex, unit, sizeof(unit_t) + unit->size);
auto elderUnit = reinterpret_cast<unit_t *>(elderUnitList + elderUnitListIndex);
elderUnit->data = reinterpret_cast<uint8_t *>(elderUnit) + sizeof(unit_t);
elderUnit->block = nullptr;
if (0 == elderUnitListIndex)
{
elderUnit->nextUnit = elderUnit;
elderUnit->prevUnit = elderUnit;
}
else
{
elderUnitList->prevUnit->nextUnit = elderUnit;
elderUnit->prevUnit = elderUnitList->prevUnit;
elderUnit->nextUnit = elderUnitList;
elderUnitList->prevUnit = elderUnit;
}
// update elder unit reference
m_refUnits[elderUnit->refIndex] = elderUnit;
elderUnitListIndex += sizeof(unit_t) + elderUnit->size;
}
// move alive units to the front of the block
auto unitMoveToPosition = reinterpret_cast<unit_t *>(block->data);
size_t usedTotalSize = 0;
if (0 == aliveUnits.size())
block->usedList = nullptr;
for (auto &unit : aliveUnits)
{
memcpy(unitMoveToPosition, unit, sizeof(unit_t) + unit->size);
unitMoveToPosition->data = reinterpret_cast<uint8_t *>(unitMoveToPosition) + sizeof(unit_t);
if (0 == usedTotalSize)
{
block->usedList = unitMoveToPosition;
unitMoveToPosition->nextUnit = unitMoveToPosition;
unitMoveToPosition->prevUnit = unitMoveToPosition;
}
else
{
block->usedList->prevUnit->nextUnit = unitMoveToPosition;
unitMoveToPosition->prevUnit = block->usedList->prevUnit;
unitMoveToPosition->nextUnit = block->usedList;
block->usedList->prevUnit = unitMoveToPosition;
}
usedTotalSize += unitMoveToPosition->size + sizeof(unit_t);
unitMoveToPosition = reinterpret_cast<unit_t *>(unitMoveToPosition->data + unitMoveToPosition->size);
}
// reset free unit list
block->freeTotal = block->size - usedTotalSize - sizeof(unit_t);
block->freeList = reinterpret_cast<unit_t *>(block->data + usedTotalSize);
block->freeList->data = reinterpret_cast<uint8_t *>(block->freeList) + sizeof(unit_t);
block->freeList->block = block;
block->freeList->size = block->freeTotal;
block->freeList->nextUnit = block->freeList;
block->freeList->prevUnit = block->freeList;
// update used unit reference
if (nullptr != block->usedList)
{
unit = block->usedList;
do
{
m_refUnits[unit->refIndex] = unit;
unit = unit->nextUnit;
} while (unit != block->usedList);
}
}
block = block->nextBlock;
} while (block != m_blocks);
resumeTheWorld(threadHandles); // 使用相同类型的替身
}
其中elderUnitList就是我们用来模拟老年代的另外申请的内存块。
另外在内存标记整理算法的基础上加了个判断,当内存单元的GC存活次数>= 4的时候,我们就把它移动到老年代的内存块上,并更新内存单元的指针引用。
当在所有的已使用内存单元都成为老年代的情况下,我们还需要将当前内存块的已使用内存单元链表设置为nullptr。
这里分代的基本思路就是将内存分为新生代与老年代,其中新生代就是我们当前的内存池,老年代就是另外申请的那一块大小32MB的内存。发生GC时我们只对新生代做操作,而进入老年代的内存单元基本移动到老年代的内存块上之后就放手不管了,并且设定进入老年代的条件是内存单元能活过4次GC的调用(GC的调用基本只会发生在内存池无法再申请内存的情况下,除非手动调用)。
写段代码来看看效果
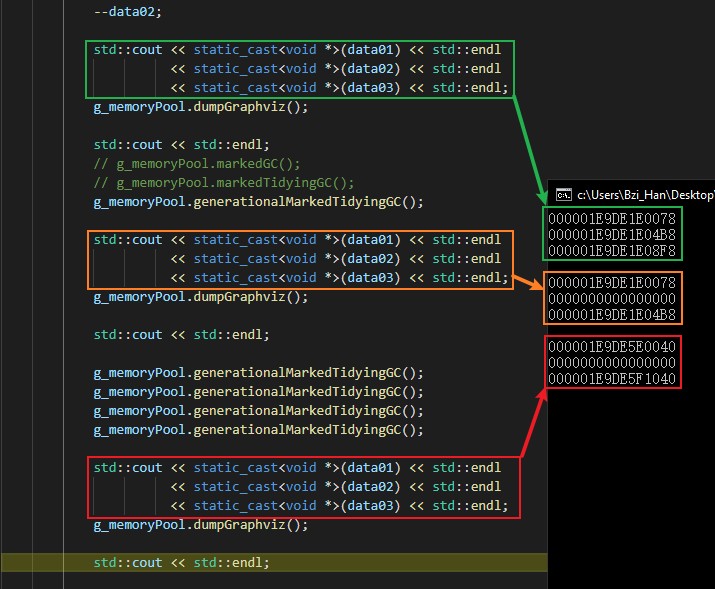
可以看到第一次GC之后进行了一次内存整理,并回收了引用计数为0的data02。接下来再进行4次GC,但真正执行的其实只有3次,第4次进去后因为判断到内存块的usedList为nullptr,所以就直接进行了返回。这表明前3次已经将存活次数>= 4的test01与test03两个对应的内存单元移动到了老年代内存块上了。
来看一下内存结构变化的Graphviz图
 |
 |
 |
|---|
可以看到运行到最后内存池已不存在使用中的内存单元,所有的内存均已归还,而被使用了的内存单元则被转移到了老年代内存块之上,那么来看一下老年代内存块的Graphviz图

这两个内存单元就是我们的test01与test03,移动正确。
GC前后的操作
在没有必要的时候我们要尽量避免GC的调用,可在仅当内存池超过限定最大可向系统申请的内存大小时才启动GC进行垃圾回收,并且避免手动的去调用GC。
在GC后若仍无法分配内存则抛出异常std::bad_alloc。
以上说的两个操作只需要在运行时做一些判断即可,在这里就不实现了,那么到这里我们所要探讨的几种垃圾回收机制就整完了,接下来我们回到GC之前。
C++使用特化
为了方便使用,来实现两个简单的包装函数。
template <typename class_t>
class_t &object() requires std::is_pod_v<class_t>
{
return *reinterpret_cast<class_t *>(alloc(sizeof(class_t)));
}
template <typename class_t, typename... params_t>
class_t &object(params_t &&...params)
{
class_t *placement = (class_t *)alloc(sizeof(class_t));
if (nullptr == placement)
throw std::bad_alloc();
new (placement) class_t(std::forward<params_t>(params)...);
return *placement;
}
然后测试一下
 |
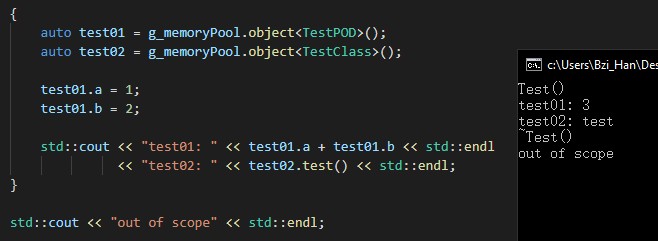 |
|---|
然后我这里不需要容器的支持(主要是懒得实现std::allocator),直接对其禁用。
先在外部声明一个concept
template <typename any_t>
concept is_container = requires(any_t any)
{
{any.size()};
{any.begin()};
{any.end()};
};
然后再实现函数
template <typename class_t, typename... params_t>
class_t &object(params_t &&...params) requires is_container<class_t>
{
static_assert(false, "Unsupported type of container.");
return {};
}
测试

差不多就这样了。
结语
想起还有一件事没做,就是在allocUnit的时候需要对齐sizeof(void*),不过在这里就不再实现了,鸭蛋莫鸭蛋。
那就这样了,有缘再见~